Ведущий разработчик.
Специализация — Рельсы, фронтенд, автоматизация тестирования и разработки.
Связаться: vasily@polovnyov.ru или телеграм.
Ведущий разработчик.
Специализация — Рельсы, фронтенд, автоматизация тестирования и разработки.
Связаться: vasily@polovnyov.ru или телеграм.
Иногда никак не хочется подходить к задаче. Уже все дела попеределал, книгу почитал, зубы почистил, на балконе прибрался, даже в машину омывайку подлил, а до задачи руки никак не доходят. Прокрастинация на максимум, не те вайбы.
В таких случаях важно не путать дизмораль с трением. В первом случае к задаче не подойти, потому что все уныло, какой в этом смысл, это ни на что не повлияет, уже три года это говно пилим. Во втором случае к задаче не подойти, потому что она реально сложная и непонятно, с какого конца за нее взяться. Соответственно, и решения разные. Дизмораль можно победить действиями вне задачи, ну или просто затащить ее на морально-волевых и дисциплине. А сложную задачу — разбить на пачку задач попроще, которые постепенно рассеивают «туман войны», спрятавший ее решение.
Поэтому первое, что я спрашиваю у себя в понедельник утром, когда чувствую непреодолимое желание пойти подлить омывайки: это дизмораль или трение?
Иногда нам достаются задачи, которые не закрыть в течение одного дня. Скажем, вы исследуете сложный баг, проявляющийся только у 0,0001% пользователей. Или вместе с архитектором пишете спеку нового сервиса, встречаясь каждую неделю на час. Или подбираете и пробуете self-hosted альтернативы Sentry. Или работаете над большой миграцией данных на новую схему.
Вдруг наступает пятница, а за ней выходные. Вы возвращаетесь к работе в понедельник и полчаса вспоминаете, на чем остановились.
В таких случаях стоит оставлять артефакты — заметки, комментарии, вопросы, кусочки кода, сравнительные таблицы, текущие проблемы и проверенные гипотезы. Словом, все, что поможет вернуться к задаче:
Проверии гипотезу с браузерным и системным зумом. В эмуляторе проблемы нет.
Как будем авторизовывать клиентов? Может, пойдем в сторону API Gateway?
Sentry — опенсорсный, но поднимает 6 контейнеров и требует кучу ресурсов. Как вариант — GlitchTip. У него АПИ, совместимый с Sentry и минимум лишнего функционала.
Перенесли все уиды в алиасы. Остается грохнуть колонку и убрать ссылки на mailing_list_uid.
Такие зарубки помогают ничего не забывать, быстрее возвращаться в контекст задачи и двигаться дальше в правильном направлении. Отсюда тупое правило:
Бывает, вижу в проектах именованные сабжекты в качестве хелперов для испытаний:
subject(:process) { described_class.new.process }
before do
allow(EventProducer).to receive(:emit).and_return(true)
end
context "when run twice" do
it "emits only one event" do
process
process
expect(EventProducer).to have_received(:emit).once
end
end
Это плохой, ложноположительный тест. Что бы мы не написали внутри process, EventProducer.emit всегда будет вызываться точно один раз.
Проблема в хелпере subject. Как и let, он кеширующий, мемоизирующий. После первого вызова он запоминает результат блока и в последующие вызовы сразу возвращает результат, не тригеря код в блоке.
Это легко проверить мини-тестом:
class EventProducer
def self.emit
end
end
describe "subject(:process)" do
subject(:process) { EventProducer.emit("foo") }
before { allow(EventProducer).to receive(:emit) }
context "when run twice" do
it "emits both events" do
process
process
expect(EventProducer).to have_received(:emit).twice
end
end
end
Результат:
Failures:
1) subject(:process) when run twice emits both events
Failure/Error: expect(EventProducer).to have_received(:emit).twice
(EventProducer (class)).emit(*(any args))
expected: 2 times with any arguments
received: 1 time with any arguments
# ./spec.rb:17:in `block (3 levels) in <top (required)>'
Пожалуйста, не используйте именованные сабжекты для испытаний. Лучше сделайте старый добрый метод:
def process
described_class.new.process
end
Я сразу родился айти-дедом. Когда появился Руби, я бухтел, что непонятно, куда тело цикла вставлять. Когда появлялись ЦСС-переменные, бухтел, что они нам «не нужоны», достаточно вот так и так сгруппировать селекторы. Бухтел, когда переезжали с Propotype на jQuery, а потом на Реакт. Бухтел, когда все носились с Монгой и Нодой. Бухтел с каждым релизом Рельс. Блин, да я даже из-за синтаксиса хэшей в Руби бухтел: ракеты рулят, джейсон отстой.
Сейчас в программировании все переезжают на AI-, LLM-помощников, которые «помогают» писать код. И вот тут я бухтеть не готов. Уверовал мгновенно, как попробовал Курсор.
В Курсоре по сути два основных помощника. Первый — стандартное автодополнение в процессе набора кода, к нему вопросов нет. Прикольно, но ничего особенного. Второй — чат с редактором. И вот этот режим — бомба, потому что обсуждать и делать можно как отдельные кусочки кода, так и проект целиком.
В какой-то момент я попросил в чате собрать мне консумер, аналогичный уже существующему, но с несколькими ключевыми изменениями. К нему же попросил тесты. Прошло 10 секунд и Курсор предложил мне два файла с кодом, в котором толком нечего было исправлять. Я просто принял изменения и пошел открывать 100% AI-generated Pull Request. И вот этот момент стал определяющим. Не о чем тут бухтеть, будущее уже здесь.
Короче, если вы еще не используете LLM-помощников в разработке, попробуйте Курсор. Просто перетерпите ВС Код и дайте ему неделю:
https://www.cursor.com/
Если вам интересно, как там у них все под капотом, послушайте подкаст с Лексом Фридманом:
Сейчас не хватает сил и внимания на что-то большое и осмысленное, поэтому короткая заметка на бегу.
Часто в удаленной работе не хватает чувства причастности к команде, чувства плеча, вот этого ощущения «да я в команде X». И вроде работаешь месяц, два, три, а до сих пор ощущение, будто, ты одинокий мститель в маске.
По моему опыту это ощущение команды появляется после совместных страданий, трудностей, например, какой-то адухи с пуском. Ребята, совместно преодолевшие весь геморрой, связанный с пуском, превращаются в братство. Они начинают доверять и полагаться друг на друга, потому что знают, что когда в очередной раз shit hits the fan, их коллега не сольется. Думаю, именно на страданиях, трудностях и совместном их преодолении строятся самые сплоченные команды в армии и спорте.
P. S. В августе прочитал всего ничего. Feel Good Productivity — херня. Автомобильная династия — часть про нацисткую Германию интересная, остальное херня. Типа, ничего себе, фантастически богатые еще сильнее богатеют. Неслыханно!
Ситуация: вы тестируете контроллер, который отправляет тестовое письмо со сводкой по вчерашним продажам. Под капотом контроллер обращается к классу DailySummaryEmail и вызывает метод #test. Вы пишете тест:
it "calls DailySummaryEmail#test" do
Это плохое, «машинное» описание проверки. Во-первых, тесты — это примеры использования кода, документация. Это пример чего? Чем он будет полезен читателю?
Во-вторых, это детали реализации, считай, приватный интерфейс. Если переименуем метод или класс, придется поправить и в теле проверки, и в ее описании.
В-третьих, это бесполезные детали. Я из тела проверки вижу, что вызываем DailySummaryEmail#test. Делаем-то это зачем? Чтобы что?
Лучше писать для людей, описывая то, что должно происходить в мире читателя:
it "sends previous day summary email to marketing department"
Год назад вышел подкаст Лекса Фридмана с Хикару Накамурой. Хикару — крутой шахматист-стример, специализирующийся на быстрых шахматах. Когда-то побеждал Магнуса Карлсена.
В подкасте есть интересный эпизод с обсуждением читинга в шахматах:
На 1:15:55 Лекс задает самый важный технический вопрос: сколько информации тебе нужно, чтобы читерить? Накамура отвечает, что ему хватит одного «бжж», если текущая позиция отличная, и двух «бжж», если текущая позиция обычная или нормальная. То есть ему не нужны конкретные ходы, оценки или предсказания. Ему достаточно знать ответ на вопрос: текущая ситуация на доске отличная (для меня) или нет?
Я переформулировал этот вопрос в «это … улучшает ситуацию или нет?» и стал бесконечно спрашивать себя:
Такой странный вопрос помогает мне оценивать последствия решений и изменений в долгосрочной перспективе. Помогает взглянуть на проблему в контексте времени и позиции, добавляет еще одну точку зрения и заставляет стремиться к улучшению «позиции». Спасибо, Хикару!
Есть гипотеза. Мы охереваем от перегруза, потому что понабрали слишком много обязательств. Эти обязательства тянут за собой планирование, коммуникацию и переключение доменных областей. Это и дает нам чувство разбитости и усталости.
Попробую показать на примере. Представим, что я подписался запрограммировать встраиваемый платежный виджет, сделать код-ревью в соседнем проекте о барсуках, выполнить мастера спорта по тяжелой атлетике, самостоятельно вести бухгалтерию в ИП и оптимизировать билд на CI, чтобы он укладывался в 3 минуты.
Каждый из этих проектов тянет за собой свою доменную область, которую надо восстанавливать в памяти. Тут у нас мерчанты и платежи. Тут барсуки, передержки и ветеринарки. Тут рывок, толчковая тяга и подрыв. Тут УСН, ПСН, счета, акты и ЭДО. Тут CI, yaml и профайлер. Любой, кто пробовал быстро переключить внимание между барсуками и УСН, знает, что это непросто. Мозг тупит и кипит минут 15-20. Есть риск задекларировать барсука.
Также каждый из этих проектов тянет за собой коммуникацию и планирование. Что там по дедлайнам у виджета? Нужно попросить у дизайнеров фотки барсуков на передержке. Не забыть зарегаться на соревнования по ТА. Акт не прошел в СБИС через роуминг, надо написать в техподдержку. Надо показать ПР с ускорением билда ребятам, чтобы покритиковали. Это тоже работа, которая также требует времени и внимания.
И кажется, что мы понабрали так много всего, потому что это «легко». Легко ревьюить соседний проект, это же не код писать. Легко выполнить мастер спорта по ТА, просто делай, что в программе написано. Легко вести ИП, в Эльбе уже все есть, только кнопки нажимай. Легко оптимизировать билд на CI, ты же программист.
Сколько обязательств вы взяли, потому что это казалось «легко»?
Вот сидишь ты в собственном кубикле, работаешь там, тут остановился и увидел сообщение в чате:
Джон, пересматриваю все формы, а у меня почему-то локально на десктопе с последней версией мастера формы распёрло. Внутри вёрстка такая же, как и была.
И чё? Что с этим делать-то? Куда бежать? Чем помочь?
Чтобы не тратить время и внимание коллег на лишние ДУМАНИЯ, лучше всё рабочее общение сводить к двум типам сообщений: просьбам и вопросам. Соответственно, сообщение выше лучше переформулировать в вопрос:
Пересматриваю формы, а у меня на десктопе с последним мастером распёрло формы. Вёрстка не менялась. Что бы это могло быть? Что из последних изменений могло повлиять?
Или в просьбу:
Пересматриваю формы, а у меня на десктопе с последним мастером распёрло формы. Верстка не менялась. Помоги, пожалуйста, отдебажить
Также и с другой стороны. Если вам пишут непонятное и загадочное, попросите сформулировать просьбу или вопрос.
Дефолтный box-sizing в ЦСС. Спасибо, ИЕ!
Все знают, что верстку нужно начинать с заклинания, переключающую блочную модель с инопланетной на человеческую:
*,
*::before,
*::after {
box-sizing: border-box;
}
Если этого не сделать, будет работать значение по умолчанию, box-sizing: content-box, то есть падинги и бордеры не будут входить в ширину элемента. Соответственно, если сказать инпутам width: 100%, они переполнят форму, потому что их ширина будет равна 100% + падинги + бордеры.
Мне такое поведение всегда казалось всратым. Если я измеряю коробку для обуви, то ее ширина — это ширина коробки, а не обуви внутри.
Оказывается, появлением вменяемой блочной модели мы обязаны Интернет Эксплореру:
Specifically, IE was treating width to include the border and the padding while CSS1 treated width as including only the content. This became known as the “IE box model”.
In 1998 the Web Standards Project compiled a list of IE’s many CSS failings, including this one.
Еще чуть больше подробностей:
https://www.jefftk.com/p/the-revenge-of-the-ie-box-model
Ищу сообразительного стажёра, который вместе со мной будет делать крутые бэкендерские штуки и со временем станет крепким медлом.
Я ищу стажёра, который:
За полтора месяца научу стажёра:
Для этого стажёр будет:
После стажировки мы либо продолжим работать вместе, либо стажер уйдёт с планом роста и списком рекомендуемой литературы.
Если написанное выше про вас, напишите мне письмо с рассказом о себе: vasily@polovnyov.ru
Если открываю код, написанный мною полгода-год назад, и мне не стыдно за него, то это плохой знак. Скорее всего, я не развиваюсь. Скорее всего, это не 5 лет опыта, а 1 год, повторённый 5 раз. Скорее всего, меня вот-вот выпрут из профессии и отправят программировать на Битриксе или 1С (no offence). А если серьёзно, то «стыд» за старый код должен появляться по двум причинам.
Во-первых, я могу вырасти как программист. Тут удачнее был бы паттерн А, тут лучше бы всё завернуть в консёрн Shareable, а вот здесь надо быть осторожнее с таймаутами на той стороне.
Во-вторых, я могу вырасти как специалист, набраться продуктового опыта. Тут мы зря разрешили кастомизировать урлы, все пользуются дефолтными. Зря сразу не сделали купоны с фиксированной ценой. Жаль, не предусмотрели, что люди могут дарить N подарков за раз.
P. S. Не менее важный сигнал — желание всё переписать. Если смотрю на старый код, замечаю проблемы и неудачные решения, а желания всё переписать нет, значит, я уже выгорел в угли.
В июле мой дорогой брат Ниязыч подарил мне 3д-принтер, мойку-сушку и два литра смолы. С тех пор я открыл 3д-типографию на балконе и стал 3д-издателем. Печатаю детские игрушки: котиков, единорогов, драконов и накачанных Пикачу.
У меня фотополимерный 3д-принтер. Он печатает с помощью фотополимерной смолы. Смола по умолчанию жидкая, но если посветить на нее особой длиной волны, затвердевает. Принтер печатает модельку слой за слоем, «запекая» их на платформе. Я наливаю смолу в ванночку с прозрачным дном, принтер опускает в нее платформу и засвечивает через дно текущий слой. Слой затвердевает и прилипает к платформе. Принтер поднимает платформу, отрывая запекшийся слой, и повторяет процесс для следующих слоев.
У такого способа печати бывают проблемы. Скажем, если слой слишком большой, принтер не сможет его оторвать и он останется на дне ванночки, похерив все последующие слои. Если слою не к чему прилепиться, если нет подпорок, он отвалится, станет плавать в ванночке и портить последующие слои.
При этом цена ошибок высока. Скажем, котик печатается 12 часов. Если вовремя не заметить проблему, легко похерить смолу и 12 часов печати. Еще и принтер придется «сбрасывать»: очищать ванночку, убирать с нее проблемный слой, фильтровать остатки смолы и все чистить.
Чтобы вовремя замечать проблемы и не терять время, я использую «Гвозди в гусенице»:
90% проблем ловятся на первом гвозде. Если первые слои не смогли закрепиться, то и печатать дальше нет смысла, поэтому первый гвоздь — как можно ближе к началу. Оставшиеся проблемы ловятся на втором гвозде, половине модельки.
Конечно, бывают сложные модели, у которых проблемные слои будут к концу печати. Но останавливать в таком случае печать не хочется. Проще дать модельке допечататься, отрезать неудачный элемент, напечатать его в другой заход и подклеить.
Гвозди работают везде. Поручили младшему разработчику задачу на 5 дней, договоритесь о гвоздях. Через день проверьте направление мысли и модель решения задачи, через 3 дня — готовность половины работы. Если что-то пойдет не так, вовремя заметите и скорректируете.
Мне тяжело неделями пилить новые фичи. Фичи связаны с неопределенностью — мы не совсем понимаем, куда идем, что нас ждет впереди, что мы забыли или не учли. Короче, очень много энергии уходит на ДУМАНИЯ. Если пилить новые фичи 6 недель подряд, можно здорово выгореть.
С другой стороны, мне легко исправлять баги. Баги тоже связаны с неопределенностью, но другого вида — мы не понимаем их причину. Зато мы знаем, как работает сейчас и как должно работать. Бац, бац и багфикс готов. Еще полчаса и он уже в продакшене. Красота!
Поэтому я предпочитаю чередовать фичи и баги. Когда чувствую, что не могу больше пилить новое, переключаюсь на баги и отдыхаю. Это работает на уровне итераций и ежедневной работы. В первом случае после 6 недель работы над новыми фичами, мы планируем разгрузочную неделю на рефакторинг и багфиксы. Во втором случае я каждый день беру баг-два, чтобы передохнуть. Периодизация!
Конечно, это не касается гейзенбагов, пожирающих твою душу. Их нужно планировать, отслеживать гипотезы и планомерно исследовать день за днем. Их лучше запихивать «продуктовым налогом» в ближайшие итерации.
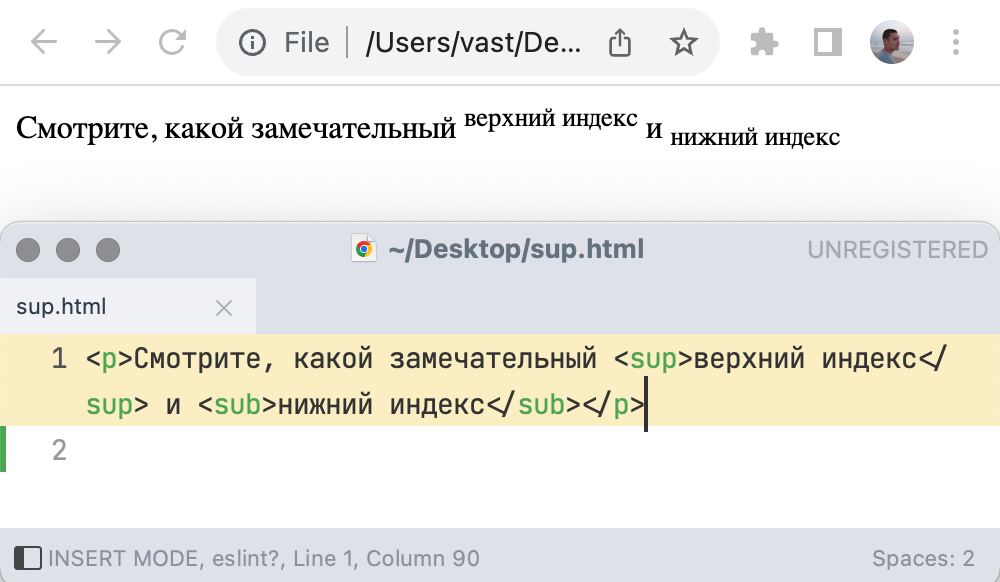
Если сделать текстовый файлик, написать в него немного текста и тегов и открыть в браузере, то текст все равно будет стилизован. Индексы работают, задан какой-то кегль и интерлиньяж.
Так происходит потому, что у браузеров есть user agent stylesheets — цсс-стили, встроенные в сам браузер. То есть это не какое-то дефолтное поведение отдельных текстовых нод, а буквально цсс-файл, который браузер подключает в первую очередь ко всем страницам. И конечно, именно с этих стилей начинается каскад: стили браузера → стили страницы → стили пользователя.
Такое поведение — часть спецификации CSS2:
User agent: Conforming user agents must apply a default style sheet (or behave as if they did). A user agent’s default style sheet should present the elements of the document language in ways that satisfy general presentation expectations for the document language (e.g., for visual browsers, the EM element in HTML is presented using an italic font). See A sample style sheet for HTML for a recommended default style sheet for HTML documents.
И конечно, эти стили можно посмотреть: опен-сорс, все дела. Например, Хром:
https://chromium.googlesource.com/
Сафари:
https://trac.webkit.org/
Фаерфокс:
https://searchfox.org/mozilla-central/source/layout/style/res/html.css
Эти стили стоит глянуть, чтобы офигеть (1000 строк!), лучше понять ЦСС (head { display: none }) и подсмотреть прикольные трюки.
Бывает, в сложных и проблемных ситуациях хочется просто забить и ультануть: внезапно уволиться с работы и стать плотником, бросить семью и уйти в ЧВК, написать клиенту, что умерла бабушка, и пропасть, пушнуть в мастер с форсом. В таких случаях ты получаешь мгновенное облегчение, а с другой стороны, просто сваливаешь, вывалив ушат говна на тех, кто на тебя надеялся. Совсем не круто.
В последний год я научился справляться с такими желаниями с помощью мантры «Просто не делай херни и…». Жопа на работе — просто не делай херни и подумай, как разгрести. Жопа в семье — просто не делай херни и подумай, как восстановить отношения. Не успеваешь с проектом — просто не делай херни и поговори с клиентом. Хочешь форспушнуть в мастер — просто не делай херни и разрезолви конфликт. Короче, просто не делай херни.
Знающие люди подсказывают, что это называется «Профессиональное самоубийство».
Как конкретно разгребать ситуации, кажущиеся неподъемными и ужасными — тема отдельного поста. Если коротко, то нужны две вещи: уверенность в том, что проблемы решаются делом, и «паззлы».
В ноябре я попал в жесткое ДТП и серьезно поехал кукухой по безопасности. Исключением не стал и дом: я накупил огнетушителей, детекторов дыма и датчиков протечки. Один из датчиков бросил под ванну, убедился, что он работает, и забыл.
В прошлое воскресенье случайно заглянул под ванну и обнаружил течь: вода подкапывает на стыке сифона и трубы канализации. Датчик при этом молчит: воды вытекает мало, она быстро испаряется и не успевает разлиться до датчика. То есть датчик есть, работает, но его как бы и нет.
Так и в программировании. Мониторим регулярность бэкапов, а когда приходится что-то достать из бэкапа, оказывается, что дампы битые и не восстанавливаются. Проверяем очередь платежей, отправляем алерты в Sentry, а они не доходят до девопсов: интеграция с PagerDuty отвалилась. Мониторим доступность сайта, а форма, через которую клиенты записываются на пробные занятия, сломалась из-за ошибки в скрипте на странице: сайт работает, форма есть, денег нет.
Что с этим можно поделать? Во-первых, убедиться, что датчики проверяют то, что нужно. Во-вторых, убедиться, что датчиков хватает. В-третьих, ввести регулярные «проверки связи» и sanity checks.
Самая большая ложь в разработке — фраза «сделаем когда-нибудь». Конечно, никто ничего никогда не сделает. Это прекрасная двойная ложь: врем себе и остальным, будто задача важна, и врем себе, что обязательно до нее доберемся.
Если у задачи нет дедлайна, считайте, что и задачи нет. Поэтому любое «сделаем когда-нибудь» нужно либо фиксировать дедлайном, либо отпускать с миром: значит, не очень-то оно нам и нужно.
P. S. Даже если добавить «после пуска», «после майских» или «после отпусков», ситуация не изменится: никто ничего не сделает, все забудут.
Бывают люди с кармой тестировщика: что бы они не использовали, находят самые невероятные баги, заусенцы и нестыковки. Взялся пинговать ya.ru, сломал ping ¯\_(ツ)\_/¯. Самые суровые из них одарены еще и бесконечной энергией: 5 багрепортов за 10 минут для них не проблема.
Конечно, когда я был начинающим программистом, я всегда их недолюбливал: ну емана, неужели тяжело НОРМАЛЬНО пинговать? Зачем это исправлять, почему нельзя последовательно нажать A, B и C, но с минимальной задержкой в 300 мс?
Со временем до меня дошло, что такие люди — дар, а не проблема. Как программисты мы склонны использовать продукты так, как это делали бы другие программы: в строгом соответствии с инструкциями и командами. Ребята с кармой тестировщика помогают делать отличные продукты, которые учитывают человеческие слабости, а не бьют за них по рукам. Короче, если среди ваших коллег есть ребята с кармой тестировщика, обнимайте их и почаще слушайте.
Недавно заметил, что при запуске рельсовой консоли пропало «эхо» при присвоении. Раньше было так:
> subscription = Subscription.find(123)
=>
#<Subscription:0x00007fe17d6b6e38
id: 123,
product_id: "xxx",
status: "active">
А стало так (некруто):
> subscription = Subscription.find(123)
=>
#<Subscription:0x00007fb3f4d06588
...
Полез разбираться и узнал пару интересных вещей. Во-первых, с марта railties бандлит irb.
Это нужно для того, чтобы ребята со старым Руби все равно получили новый irb вместо «системного» старья.
Во-вторых, новый irb по умолчанию обрезает «эхо» при присвоении:
В-третьих, чтобы вернуть «эхо», достаточно подкрутить конфигурацию irb в ~/.irbrc:
IRB.conf[:ECHO_ON_ASSIGNMENT] = true
Там же можно вырубить всратое автодополнение:
IRB.conf[:USE_AUTOCOMPLETE] = false